The “unsigned” Conundrum
A few weeks ago, CppCon16 conference organizer Jon Kalb gave a great little lightning talk titled “unsigned: A Guideline For Better Code“. Right up front, he asked the audience what they thought this code would print out to the standard console:

Even though -1 is obviously less 1, the program prints out “a is not less than b“. WTF?
The reason for the apparently erroneous result is due to the convoluted type conversion rules inherited from C regarding unsigned/signed types.
Before evaluating the (a < b) expression, the rules dictate that the signed int object, a, gets implicitly converted to an unsigned int type. For an 8 bit CPU, the figure below shows how the bit pattern 0xFF is interpreted differently by C/C++ compilers depending upon how it is declared:
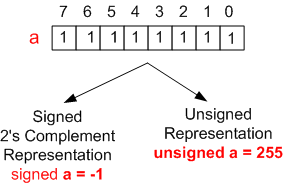
Thus, after the implicit type conversion of a from -1 to 255, the comparison expression becomes (255 < 1) – which produces the “a is not less than b” output.
Since it’s unreasonable to expect most C++ programmers to remember the entire arcane rule set for implicit conversions/promotions, what heuristic should programmers use to prevent nasty unsigned surprises like Mr. Kalb’s example? Here is his list of initial candidates:

If you’re trolling this post and you’re a C++ hater, then the first guideline is undoubtedly your choice :). If you’re a C++ programmer, the second two are pretty much impractical – especially since unsigned (in the form of size_t) is used liberally throughout the C++ standard library. (By the way, I once heard Bjarne Stroustrup say in a video talk that requiring size_t to be unsigned was a mistake). The third and fourth guidelines are reasonable suggestions; and those are the ones I use in writing my own code and reviewing the code of others.
At the end of his interesting talk, Mr. Kalb presented his own guideline:

I think Jon’s guideline is a nice, thoughtful addition to the last two guidelines on the previous chart. I would like to say that “Don’t use “unsigned” for quantities” subsumes those two, but I’m not sure it does. What do you think?
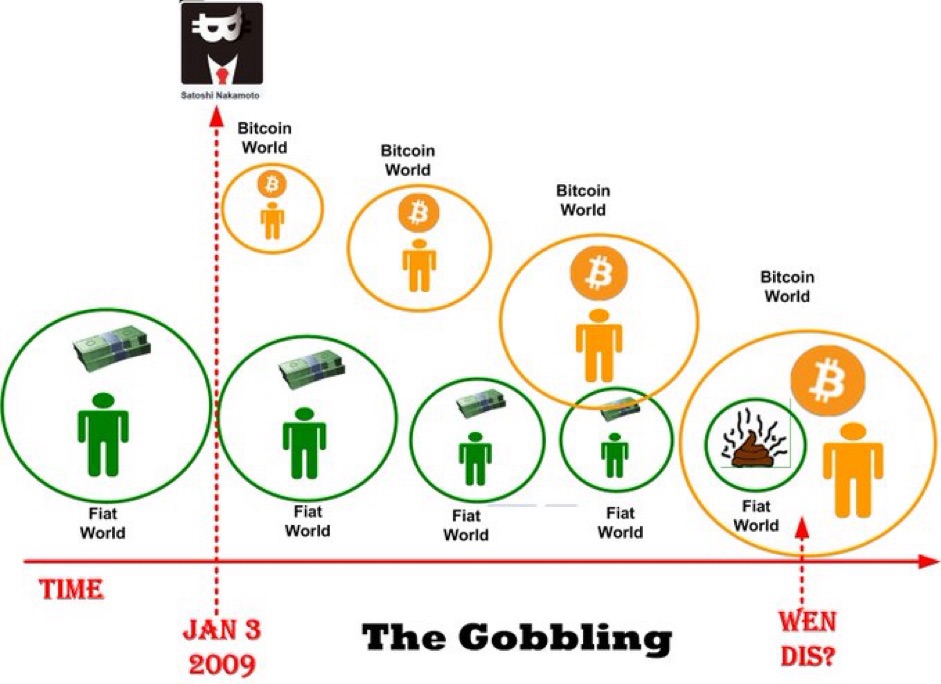
Wen Gobbling?
Fuggedaboud the next Bitcoin halving. As the figure below shows, I want to know when the gobbling is going to happen. We’re somewhere between the Bitcoin launch date and the gobbling, but I have no idea where. The end state is where all 160+ centralized fiat systems bend the knee to king Bitcoin.
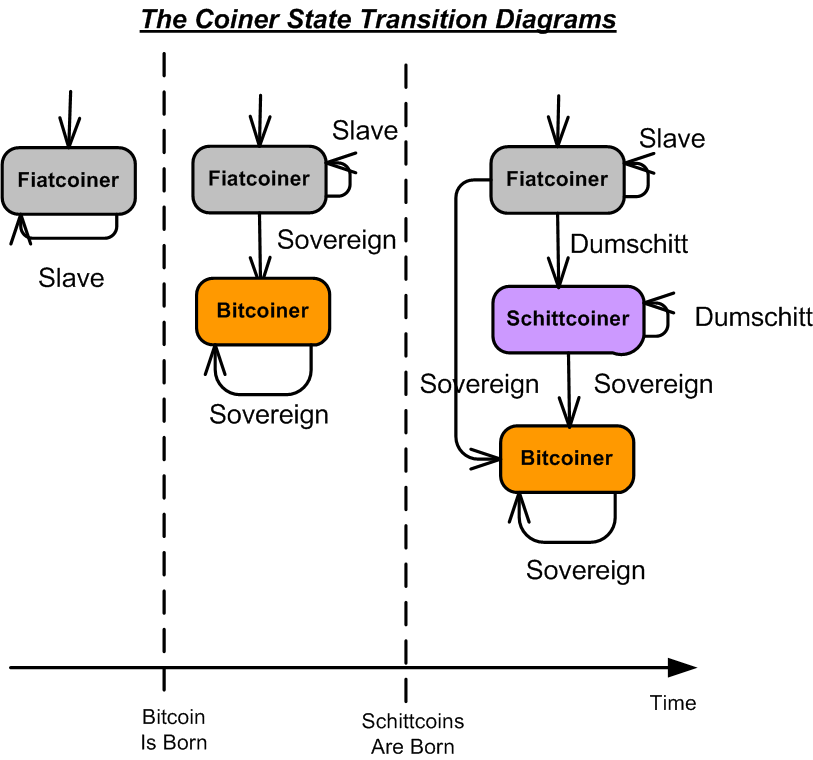
Fiatcoiner, Bitcoiner, And Schittcoiner
As the state transition diagram below shows, there are three types of coiners: Slave-Fiatcoiner, Sovereign-Bitcoiner, and Dumschitt-Schittcoiner. Before the immaculate conception that is Bitcoin, we were all Fiatcoiners, but not by choice. We were all born into one of the closed, 160+ jurisdictions in the world that required the use of Fiatcoins for daily living and tax payments. We were like fish in water as we took these Fiatcoin systems for granted that “they worked just fine”. But they don’t. Inflation, the insidious scourge designed into all fiat systems, erodes the purchasing power of all Fiatcoin holders.
Thankfully, my path to becoming a Sovereign-Bitcoiner was direct. I was lucky enough to fall down the Bitcoin rabbit hole and emerge enlightened before the plethora of Schittcoins (and yes, they include ethereum) popped up everywhere. They formed a treacherous moat between Fiatcoiners and Bitcoiners. This formidable barrier inhibited direct transitions into the enlightened Bitcoiner state.
Those Dumschitts who fell into the quagmire of centralized Schittcoin pump-and-dump schemes got rekt big time. Those horrible experiences nudged them down the bitcoin rabbbit hole, which converted them to Bitcoiners, who are all anti-Schittcoiners. Until the Schittcoin market fully implodes, direct transitions from Fiatcoiner to Bitcoiner while avoiding the Schittcoin swamp will be rare.
Notice that the Bitcoiner state has no exit transitions. Once a Bitcoiner, always a Bitcoiner In the long run, those who remain in the Schittcoiner and Fiatcoiner states will get rekt, and they’ll deserve it.
Just Because
I haven’t posted in a while because… well, just because. It’s a long story so I won’t bore you with the lurid details. We gotta keep moving forward because when motion stops, death follows. So here I am, for now.
My two favorite macroeconomic analysts are Lyn Alden and Luke Groman. They are unparalleled in their ability to convey their deep understanding of what’s going on in the world economically to lowly plebs like me. Lyn has a book coming out soon titled “Broken Money“. I can’t wait for it!
I’ve been capturing my understanding of the structure of what a typical unpegged fiat system looks like. I produced the concoction below after many maniacal iterations. I think the model is applicable to every country on earth that has a central bank to control its national fiat system. It applies to all forms of government: democracy, dictatorship, monarchy, junta, politburo, etc. If you don’t agree, then help me understand what’s wrong with the model.

The ith Bitcoin Halvening
I just got one of these stylish sweeties from an Etsy artisan shop.
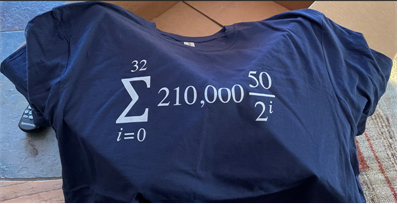
So, you ask: “WTF does that Bitcoin nerd math mean?”
Here’s BD00’s attempt at communicating the meaning of the sacred Bitcoin money-supply equation by mapping the basic math symbology into words:

So, you say: “This explanation doesn’t help at all. WTF is this ‘Halvening’ jargon?“, and you follow that up quickly with an astute, insightful, haymaker: “You think you’re smart, but you’re not… you’re an imposter.”
One of the divine features of the Bitcoin protocol is that the production of bitcoins gets abruptly cut in half approximately every 4 years. Hence, the new word, “halvening“, was concocted to commemorate those joyous supply shocks for Bitcoin cultists like me (you’re one too, you just haven’t realized it yet).
“Halvening” can be used interchangeably with “halving”. BD00 prefers the former because it’s a new beast, has 3 syllables, and reminds him of those scary “ing” movies: The Conjuring, The Shining, The Thing, Jurassic Parking, Karate Kidding, Schindler’s Listing, Deadpooling, etc.
Here’s what we get when we plot out the most hallowed, disciplined, apolitical, incorruptible, deterministic, terse, honest, “money printing” policy of all time.

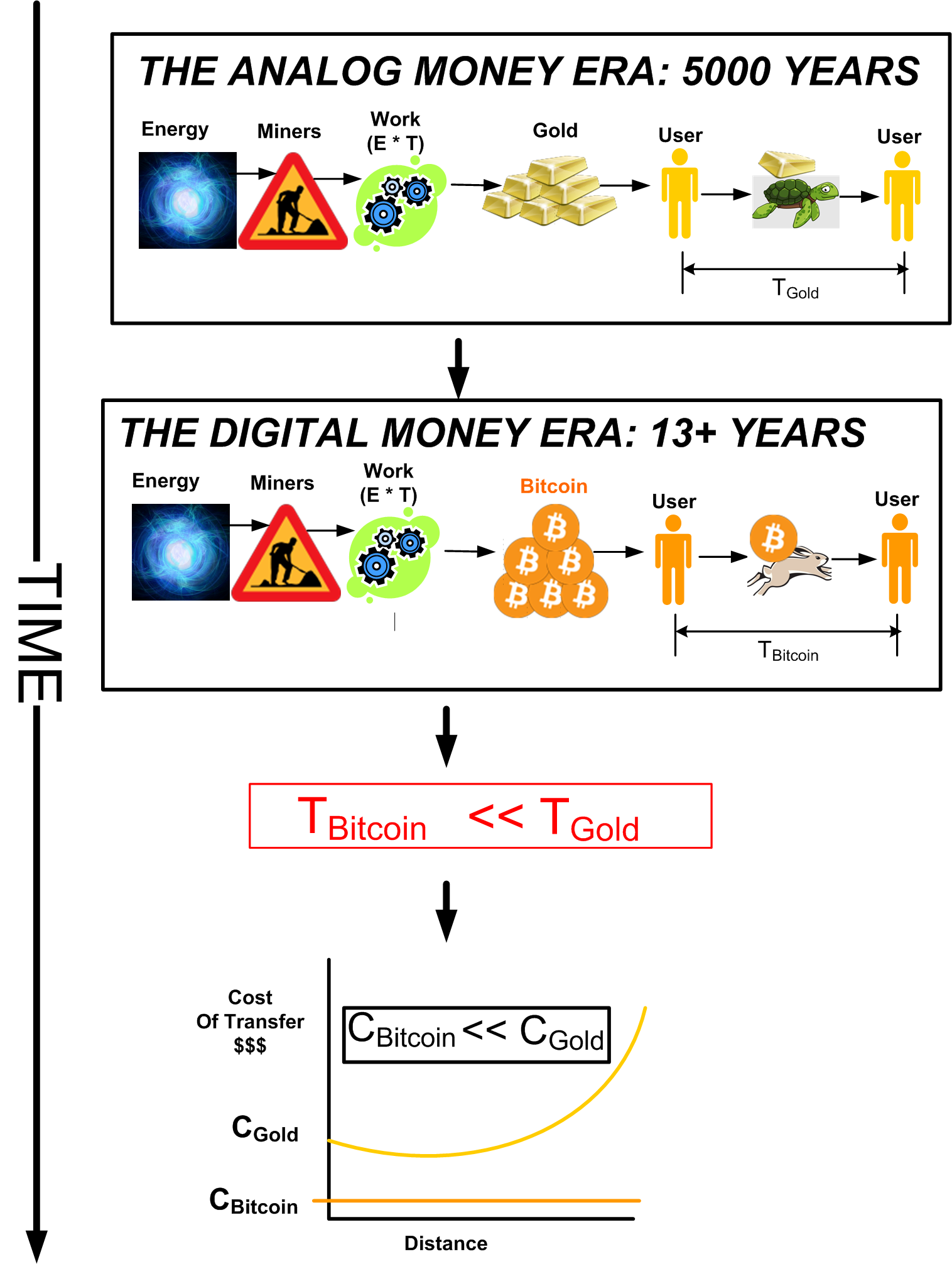
The Bitcoin network has dispassionately and automatically executed 3 halvenings since it was launched 13 years ago on January 3, 2009. Thus, the index “i” is currently set at 3 until the next halvening event occurs in 2024. It’s important to note that over 18M bitcoins, or 85% of the total supply, have already been mined to date. It’s important because hard core believers like me are steadfast HODLers (Hold On for Dear Life) that further restrict the availability of bitcoins for purchase over time in addition to the built-in protocol halvenings.

So, what’s so special about the Bitcoin money production schedule? The following composite graph, which led to an abnormally high number of views in a previous post, clearly shows the contrast between the Bitcoin mining schedule and the printing “schedules” of untrustworthy, central bank-printed, fiat paper.
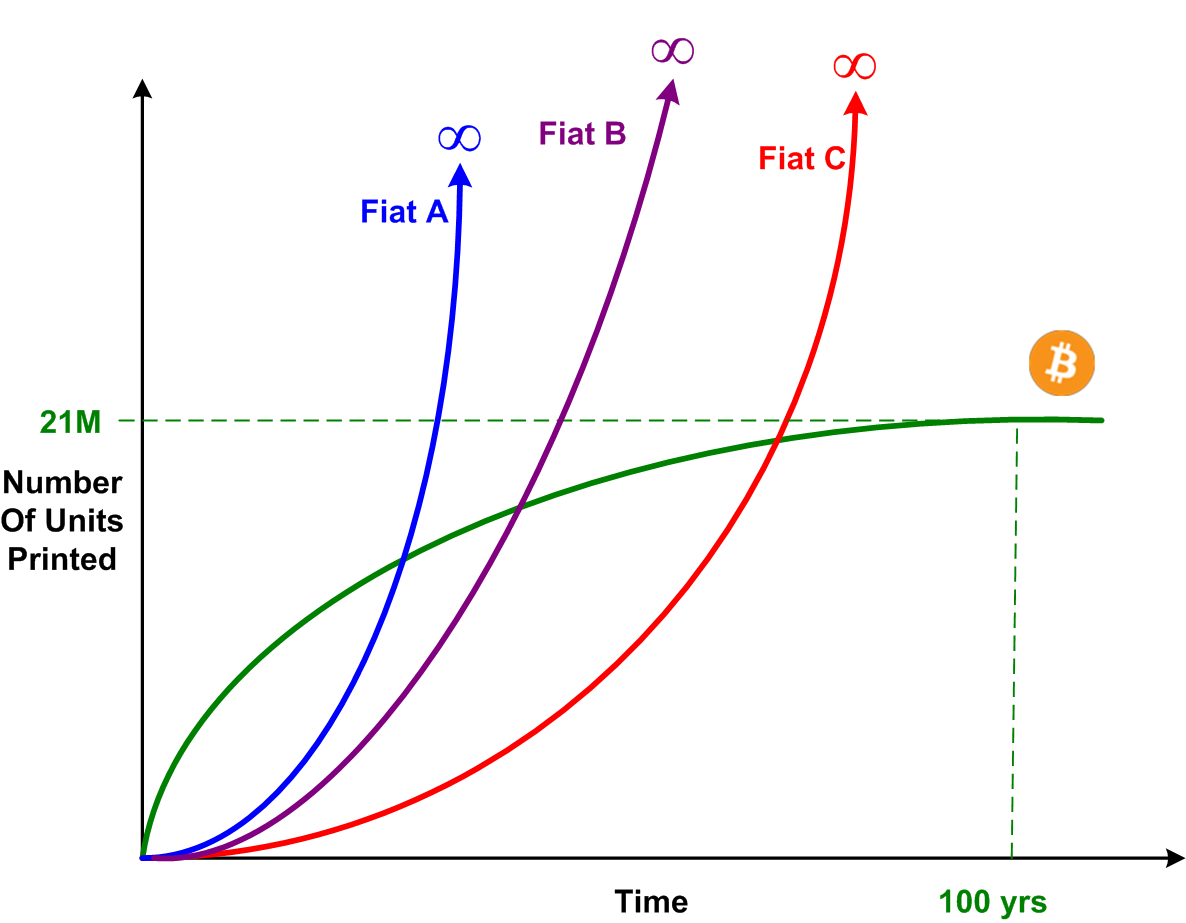
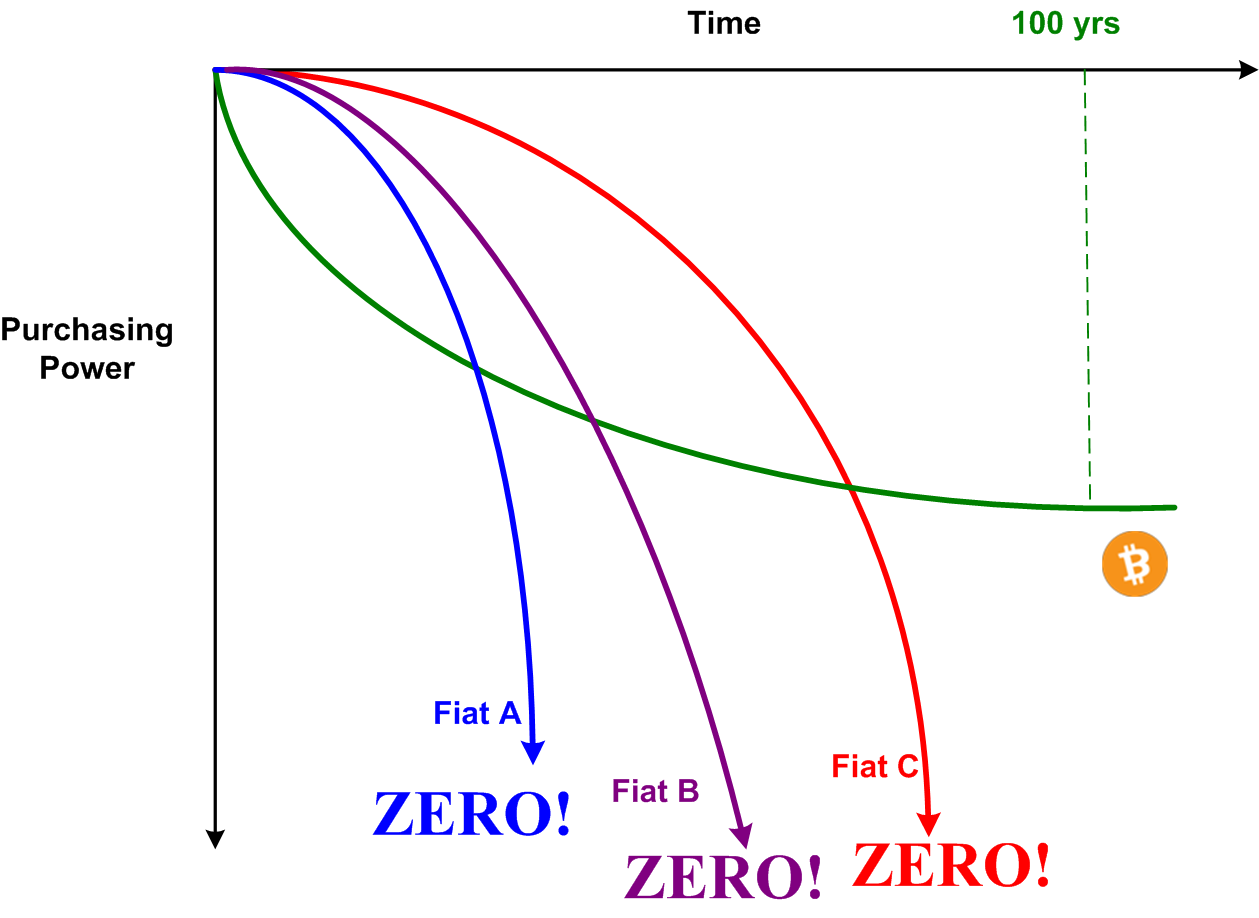
The succession of relentless halvenings executed by the decentralized Bitcoin protocol software eventually drives inflation to zero. The money printer stops forever at 21M bitcoins printed. In fiat-denominated nations, all money units are printed from one source: the country’s “independent” (lol) central bank. In every known case in history, central banks eventually are pressured by their governments to keep inflating the money supply to keep the economy roaring. Keeping inflation low takes a back seat to gorging their donors with free money. Bitcoin don’t give a fuck about donors or governments or central banks. Bitcoin don’t care if you or I use it. Bitcoin just is.
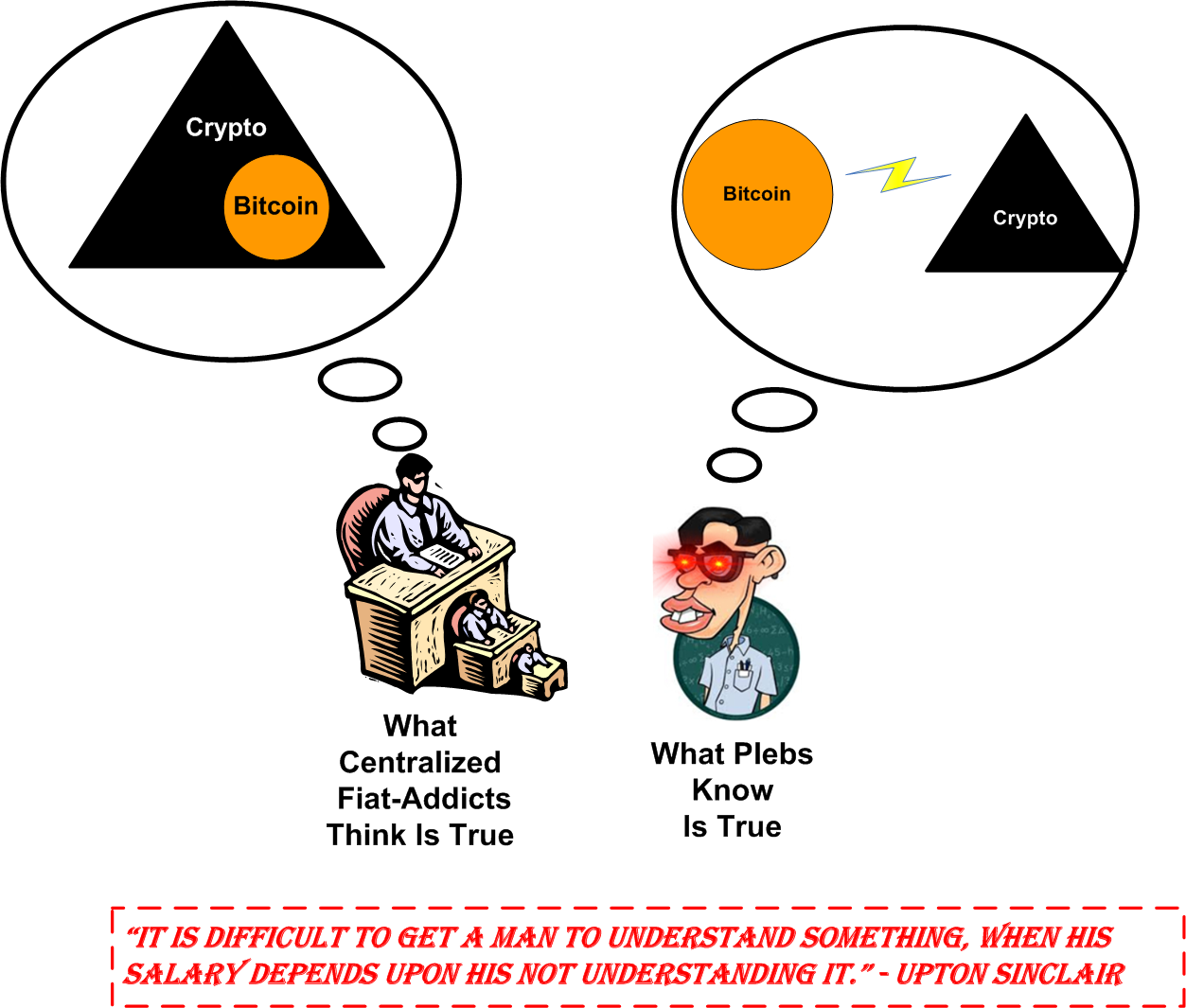
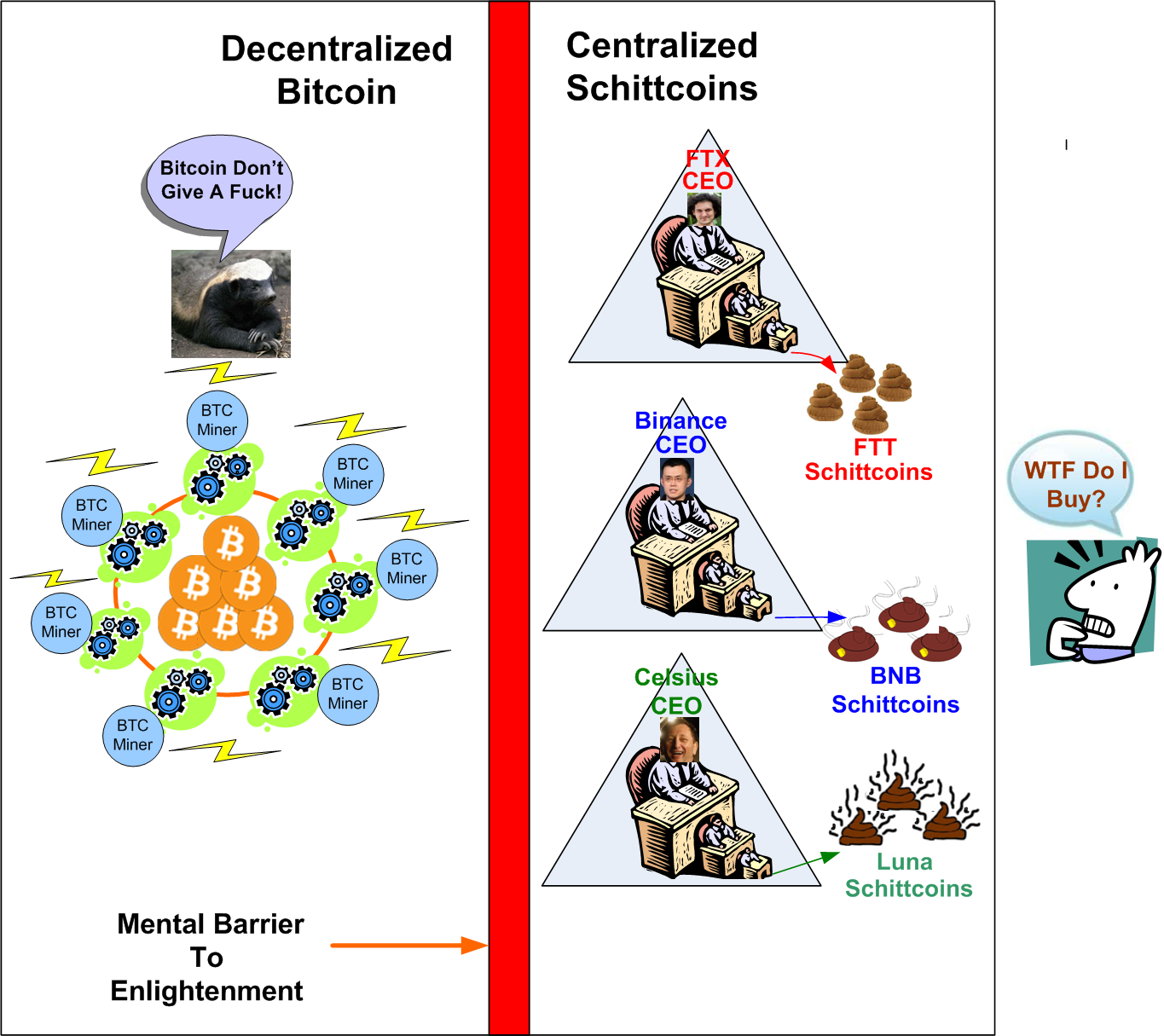
An Easy Choice
Since it took me forever to draw up this “NFT-worthy” picture and I hope it’s self-explanatory, I have no further words to say, which is amazing because I never STFU.
The Pre, The Local, The Central, The Post
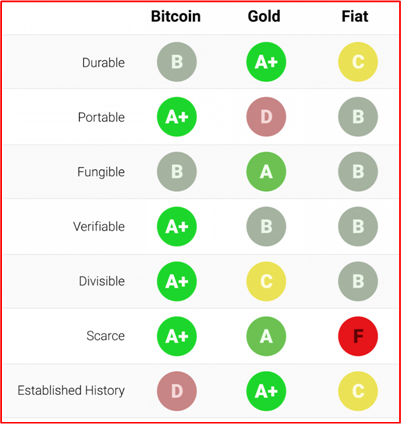
At first, we had the pre-banker era. Over thousands of years, the world slowly and haphazardly converged on gold as the most valuable form of global money compared to all other “hard” physical candidates (cows, sheep, shells, beads, rocks, salt, wheat, etc). People and nations exchanged gold more than any other medium of exchange to settle transactions. They “trusted” gold as a medium of exchange not because of any active, internal, functionality it provided (which is basically zero!), but because of the superiority of its built-in non-functional “ilities“: durability, portability, fungibility, divisibility, verifiability, scarce-ability. Haha, I know scarcity is not an “ility“, but I had to mangle the word and tack on the underappreciated “ility” suffix for consistency. The funny thing is that after 30+ years of developing software, the “ilities” have almost always been disrespected by both developers and managers. Everyone wanted the functionality, but no one wanted to pay for the “ilities”.

Over time, the banking industry arose. Rich people, who, by definition, accumulated lots of gold, could store their precious, but heavy, bulky, gold at a bank for security and receive an important-looking paper IOU in return. “Trust us” they said. If you want your gold, come back to us with the paper IOU and we’ll return your gold. LOL. These banks popped up everywhere and they all had their own unique IOU notes. Lots of banks with unscrupulous owners went bust by issuing more notes than gold deposits on hand. When people lost “trust” and they all tried to get their gold back, there wasn’t enough gold for everybody. Social unrest ensued.
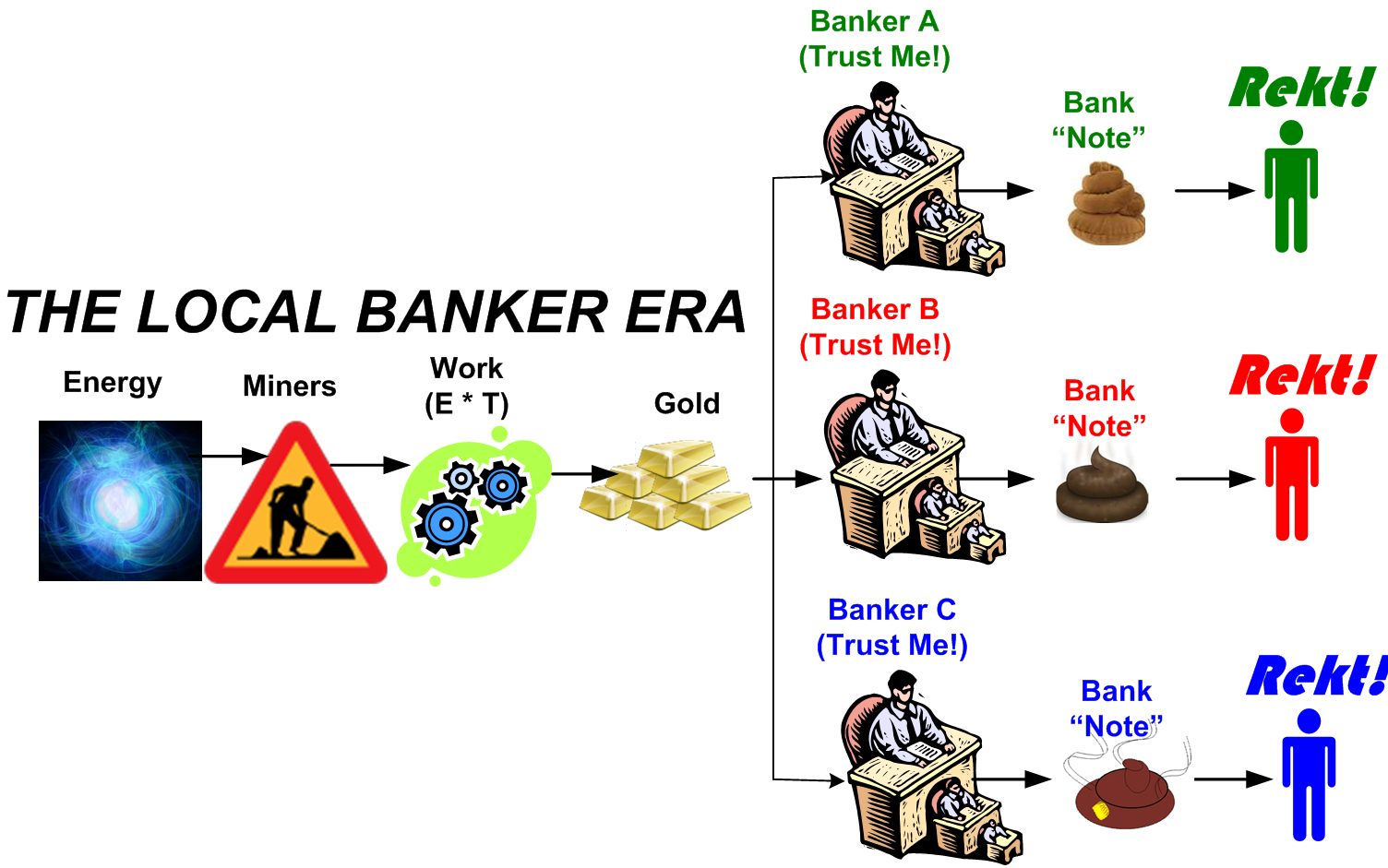
After the fragmented local bank era came the illustrious central banker phase where a group of unelected, politically appointed, bureaucratic, oracles surfaced every once in a while to say: “trust us”. LOL
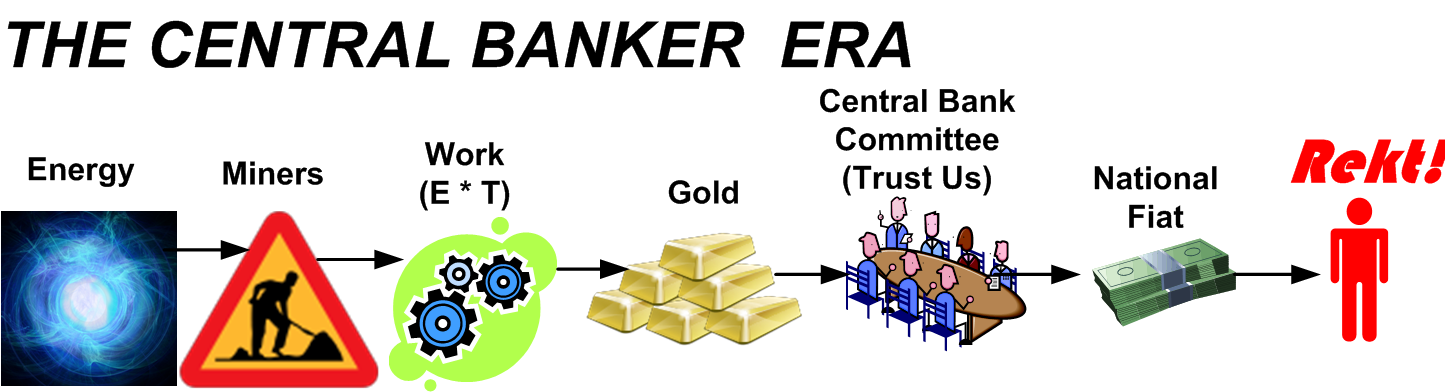
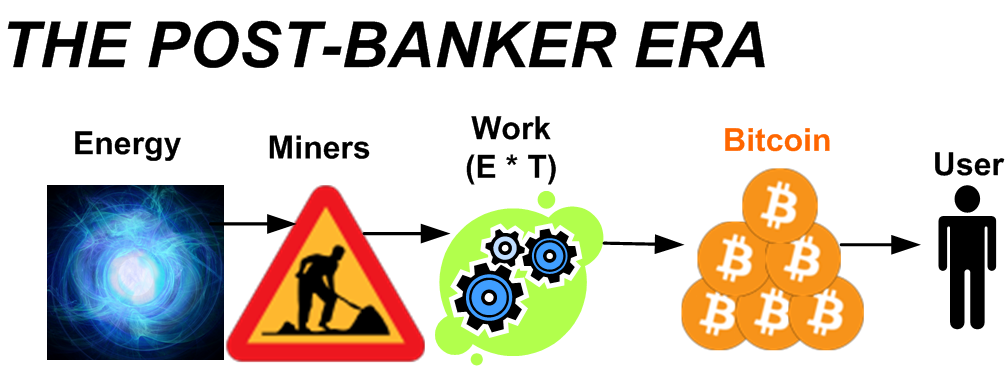
In the future, we will probably still have fiat-spewing central banks that squeeze your purchasing power from their paper IOUs by continuously printing free “money“, but we will also have a parallel, opt-in, Bitcoin-based, self-custodial, banking system in which no trust in third parties is required.
I love the following table and I’ve posted it before. I’m going to keep posting it every so-often because it really shows how Bitcoin wins the “ility” wars against gold, which in-turn wins the war against the worst form of money – sovereign fiat paper.
Bitcoin The Hare Vs. Gold The Tortoise
Just doing some Bitcoin doodling a bit here. 👇
I lost a little mojo recently, but I am rejuvenated (yet) again. The condensed version of the story is that for a few months before this week, I was convinced that the loss of feeling in my right leg and increase in pain in my lower lumbar were a one way street. Now I’m not! After 4 days of physical therapy via the direction of a McKenzie-trained therapist, I’ve felt some reversal of numbness and back pain. It’s a joyful event because it’s been months since I’ve felt this way. And the exercise (yes, singular tense), is stunningly easy to do.
Phew, just another up and down experience for a regular (but not normal) person with cancer ensconced in the patchwork medical system.
I’ll Take The Necrosis, Please!
Each of my last two brain MRI scans indicated some small growth in one of my brain tumor sites. Thankfully, the encroaching Emperor’s orc breeding ground is not the tumor site that has been wreaking havoc on my right leg for 6 years. I’ll have much more to say about my leg fiasco in a subsequent rage-post.
Because of the two successive growths, my neurosurgeon ordered a PET/CT scan of my brain to determine if the tumor tissue had resumed its inexorable growth, or whether the tissue expansion is from radiation-induced necrosis. He said he suspected the tissue to be cancerous because of the images he saw via the MRIs.
PET/CT scans measure how much “sugar” is being consumed in various parts of the body. Ravenous tumors show up as bright areas on the scan where there shouldn’t be any. Here is the report from my scan….

Thankfully, my neurosurgeon’s instinct was wrong in this case. The cause of growth was due to radiation-induced necrosis, not because of the Orc army’s continuous murderous assaults on my physical being, i.e., tumor growth. Hallelujer for necrosis!
Even though the brute-force Orc battalions are being continuously beaten back by my trusty Opdivo infusions, the dastardly clever EOAM is always diligently working upstairs, in the abstract, ensuring to insert plenty of heavy, negative, fearful, anxious thoughts in my mind whenever he can. Fortunately, reading the PET/CT scan report cleaned house upstairs and allowed lighter, more positive, hopeful thoughts to fill the void in my mind.
The Resolute Desk
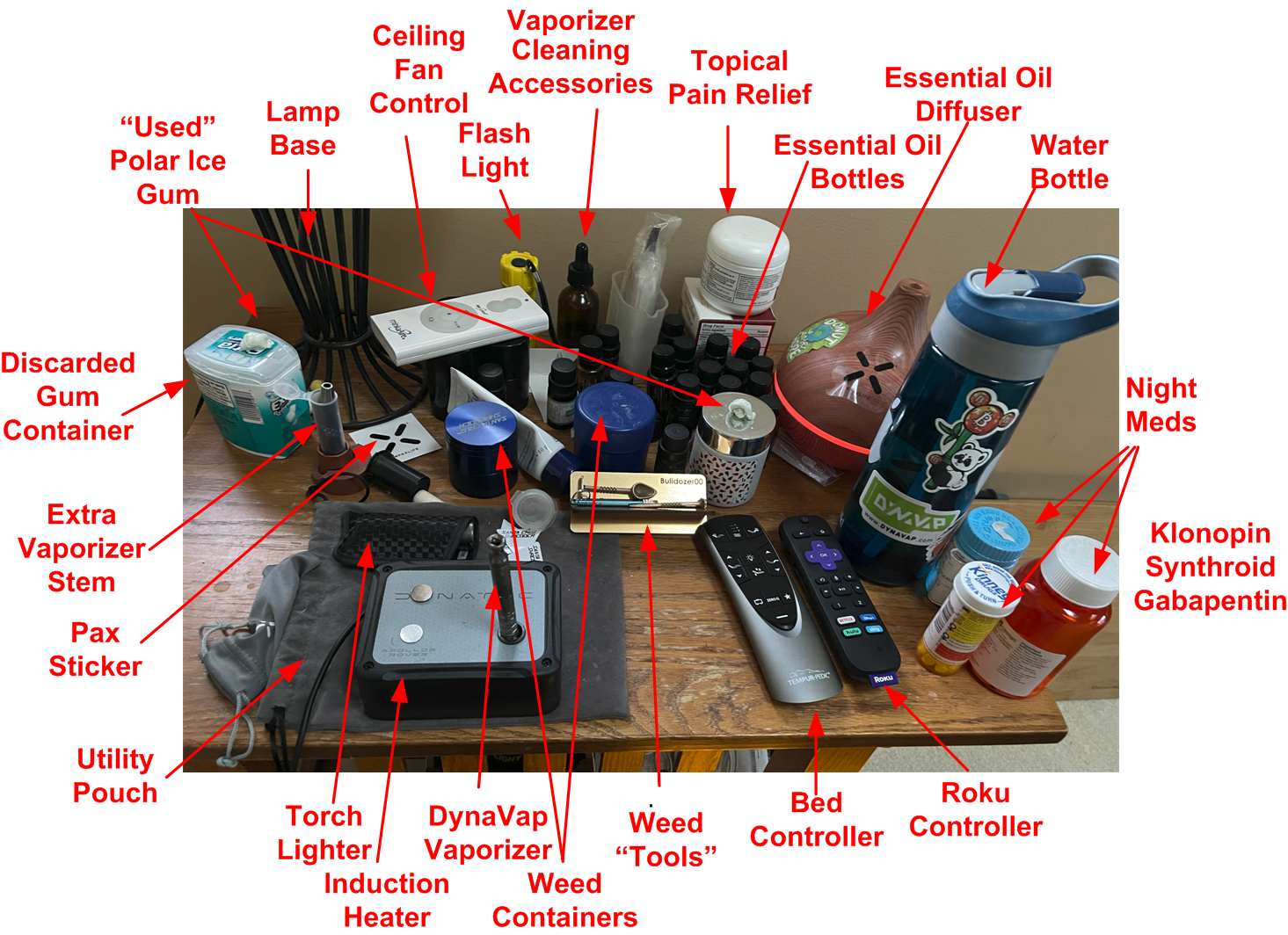
Dear OnlyFans, checkout BD00’s resolute desk below. Ok, it’s not a resolute desk. It’s a simple end table with a lot of schitt on it. The desk, along with my new, Osaki massage chair, will be cremated with me when the Emperor wins the final battle.

For those interested in WTF all those things crammed onto the desktop are, here you go…
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

