Archive
Move In, Move Out
In many application domains, the Producer-Queue-Consumer pattern is used to transport data from input to output within a multi-threaded program:

The ProducerThread creates Messages in accordance with the application’s requirements and pushes pointers to them into a lock-protected queue. The ConsumerThread, running asynchronous to the ProducerThread, pops sequences of Message pointers from the queue and processes them accordingly. The ConsumerThread may be notified by the ProducerThread when one or more Messages are available for processing or it can periodically poll the queue.
Instead of passing Message pointers, Message copies can be passed between the threads. However, copying the content can be expensive for large messages.
When using pointers to pass messages between threads, the memory to hold the data content must come from somewhere. One way to provide this memory is to use a Message buffer pool allocated on startup.

Another, simpler way that avoids the complexity of managing a Message buffer pool, is to manually “new” up the memory in the ProducerThread and then manually “delete” memory in the ConsumerThread.
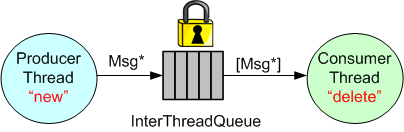
Since the introduction of smart pointers in C++11, a third way of communicating messages between threads is to “move” std::unique_ptrs into and out of the InterThreadQueue:

The advantage of using smart pointers is that no “deletes” need to be manually written in the ConsumerThread code.
The following code shows the implementation and usage of a simple InterThreadQueue that moves std::unique_ptrs into and out of a lock protected std::deque.


#include "catch.hpp"
#include <memory>
#include <deque>
#include <mutex>
#include <vector>
#include <stdexcept>
template<typename Msg>
class InterThreadQueue {
public:
InterThreadQueue(int32_t capacity) :
_capacity(capacity) {}
void push(std::unique_ptr<Msg> msg) {
std::lock_guard<std::mutex> lg(_mtx);
if(_queue.size() not_eq _capacity) {
_queue.push_back(std::move(msg));
}
else {
throw std::runtime_error{"Capacity Exceeded"};
}
}
std::vector<std::unique_ptr<Msg>> pop() {
std::vector<std::unique_ptr<Msg>> msgs{};
std::lock_guard<std::mutex> lg(_mtx);
while(not _queue.empty()) {
msgs.emplace_back(std::move(_queue.front()));
_queue.pop_front();
}
return msgs; //Move the vector to the caller
}
private:
mutable std::mutex _mtx{};
const std::size_t _capacity;
std::deque<std::unique_ptr<Msg>> _queue;
};
TEST_CASE( "InterThreadQueue" ) {
//Create our object under test
InterThreadQueue<int32_t> itq{2};
//Note: my compiler version doesn't have std::make_unique<T>()
std::unique_ptr<int32_t> dataIn{new int32_t{5}};
itq.push(std::move(dataIn));
dataIn = std::unique_ptr<int32_t>{new int32_t{10}};
itq.push(std::move(dataIn));
dataIn = std::unique_ptr<int32_t>{new int32_t{15}};
//Queue capacity is only 2
REQUIRE_THROWS(itq.push(std::move(dataIn)));
auto dataOut = itq.pop();
REQUIRE(2 == dataOut.size());
REQUIRE(5 == *dataOut[0]);
REQUIRE(10 == *dataOut[1]);
REQUIRE(0 == itq.pop().size());
}
Beginner, Intermediate, Expert
Check out this insightful quote from Couchbase CTO Damien Katz:

Threads are hard because, despite being extremely careful, it’s ridiculously easy to code in hard to find, undeterministic, data races and/or deadlocks. That’s why I always model my multi-threaded programs (using the MML, of course) to some extent before I dive into code:

Note that even though I created and evolved (using paygo, of course) the above, one page “agile model” for a program I wrote, I still ended up with an infrequently occurring data race that took months, yes months, to freakin’ find. The culprit ended up being a data race on the (supposedly) thread-safe DB2 data structure accessed by the AT4, AT6, and AT7 threads. D’oh!
Two Plus Months
Race conditions are one of the worst plagues of concurrent code: They can cause disastrous effects all the way up to undefined behavior and random code execution, yet they’re hard to discover reliably during testing, hard to reproduce when they do occur, and the icing on the cake is that we have immature and inadequate race detection and prevention tool support available today. – Herb Sutter (DrDobbs.com)
With this opening paragraph in mind, observe the figure below. If you don’t lock-protect a stateful object that’s accessed by more than one thread, you’re guaranteed to fall into the dastardly trap that Herb describes. D’oh!

Now, look at the two object figure below. Unless you protect each of the two objects in the execution path with a lock, you’re hosed!

To improve performance at the expense of higher risk, you can use one lock for the two object example like on the left side of this graphic:

Alas, if you do choose to use one lock in a two object configuration like the example above, you better be sure that you don’t come in through the side with another thread to use the thread-unsafe object2. You also better be sure that a future maintainer of your code doesn’t do the same. But wait… How can you ensure that a maintainer won’t do that? You can’t. So stick with the more conservative, lower performance, one-lock-per-object approach.
Don’t ask me why I wrote this post cuz I ain’t answering. Well, Ok, ask. I wrote this post because I was burned by the left-hand side of the second graphic in this post. It took quite awhile, actually two plus months, to finally localize and squash the bugger in production code. As usual, Herb was right.
And please, don’t tell me that lock-free programming is the answer:
…replacing locks wholesale by writing your own lock-free code is not the answer. Lock-free code has two major drawbacks. First, it’s not broadly useful for solving typical problems—lots of basic data structures, even doubly linked lists, still have no known lock-free implementations. Second, it’s hard even for experts. It’s easy to write lock-free code that appears to work, but it’s very difficult to write lock-free code that is correct and performs well. Even good magazines and refereed journals have published a substantial amount of lock-free code that was actually broken in subtle ways and needed correction. – Herb Sutter (Dr. Dobbs).
Standard, Portable C++ Concurrency
Recently, I downloaded the Microsoft Visual Studio 11 IDE Beta in order to start experimenting with some C++11 features. Lo and behold, standard and portable concurrency is now supported:

At least on Windows, there’s no need to use the Win API, Boost.Thread or ACE or any other third party library in the future to write multi-core friendly, multi-threaded C++ apps. I don’t know when GCC and/or CLANG will ship with the standard C++11 concurrency libs. Do you?
By the way, a series of quick tests verified that lambdas, strictly typed enums, auto, nullptr, std::array, std::regex, and std::atomic work. Initializer lists, raw string literals, “using” as typedef, and range-based for loops don’t work yet.
Concurrency Support
Assuming that I remain a lowly, banana-eating programmer and I don’t catch the wanna-be-uh-manager-supervisor-director-executive fever, I’m excited about the new features and library additions provided in the C++11 standard.

Specifically, I’m thrilled by the support for “dangerous” multi-threaded programming that C++11 serves up.

For more info on the what, why, and how of these features and library additions, check out Scott Meyers’ pre-book training package, Anthony Williams’ new book, and Bjarne’s C++11 FAQ page.

Persistent Discomfort
As part of the infrastructure of the distributed, multi-process, multi-threaded system that my team is developing, a parameterized, mutex protected, inter-thread message queue class has been written and dropped into a general purpose library. To unburden application component developers from having to do it, the library-based queue class manages a reusable pool of message buffers that functionally “flow” from one thread to the next.

On the “push” side of the queue, usage is as follows:
- Thread acquires a handle to the next empty Message buffer
- Thread fills Message buffer
- Thread returns handle to the queue (push)
On the “pop” side of the queue, usage is as follows:
- Thread acquires a handle to the next full Message buffer (pop)
- Thread processes the Message content
- Thread returns handle to the queue
So far, so good, right? I thought so too – at the beginning of the project. But as I’ve moved forward during the development of my application component, I’ve been experiencing a growing and persistent discomfort. D’oh!
Using the figure below, I’m gonna share the cause of my “inner thread” discomfort with you.

In order to functionally process an input message and propagate it forward, the inner thread must do the following work:
- Acquire a handle to the next input Message buffer from queue 1 (pop)
- Acquire a handle to the next empty output Message buffer from queue 2
- Utilize the content of the Message from queue 1 to compute/fill in the Message to queue 2
- Return the handle of the input message to queue 1
- Return the handle of the output message to queue 2 (push)
For small messages and/or when the messages are of different types, I don’t see much wrong with this inter-thread message passing approach. However, when the messages are big and of the same type, my discomfort surfaces. In this case (as we shall see), the “utilize” bullet amounts to an unnecessary copy. The more “inner” threads there are in the pipeline, the more performance degradation there is from unnecessary copies.
So, how can the copies be eliminated and system performance increased? One way, as the figure below shows, is to move message buffer management responsibility out of the local queue class and into a global, shared message pool class.

In this memory-less queue design, the two pipeline end point threads explicitly assume the responsibility of acquiring and releasing the Message buffer handles from the mutex protected, shared message pool. The first thread “acquires” and the last thread “releases” message buffer handles. Each inner thread, i, in the pipeline performs the following work:
- Pop the handle to the next input Message buffer from queue i-1
- Process the message
- Push the Message buffer handle to queue i
The key to avoiding unessential inner thread copies is that the messages must be intentionally designed to be of the same type.
As soon as I get some schedule breathing room (which may be never), I’m gonna refactor my application infrastructure design and rewrite the code to implement the memoryless queue + global message pool approach. That is, unless someone points out a fatal flaw in my reasoning and/or presents a superior inter-thread message communication pattern.
SysML, UML, MML
I really like the SysML and UML for modeling and reasoning about complex, multi-technology and software-centric systems respectively, but I think they have one glaring shortcoming. They aren’t very good at modeling distributed, multi-process, multi-threaded systems. Why? Because every major element (except for a use case?) is represented as a rectangle. As far as I know, a process can be modeled as either a parallelogram or a stereotyped rectangular UML class (SysML block ):

To better communicate an understanding of multi-threaded, multi-process systems, I’ve created my own graphical “proprietary” (a.k.a. homegrown) symbology. I call it the MML (UML profile). Here is the MML symbol set.

An example MML diagram of a design that I’m working on is shown below. The app-specific modeling element names have been given un-descriptive names like ATx, APx, DBx, Mx for obvious reasons.
Compare this model with the equivalent rectangular UML diagram below. I purposely didn’t use color and made sure it was bland so that you’d answer the following question the way I want you to. Which do you think is more expressive and makes for a better communication and reasoning tool?

If you said “the UML diagram is better“, that’s OK. 🙂
Monolithic Redesign
On my latest assignment, I have to reverse engineer and understand a large monolithic block of computationally intense, single-threaded product code that’s been feature-enhanced and bug-fixed many times, by many people, over many years (sound familiar?). In addition to the piled on new features, a boatload of nested if-else structures has been injected into the multi-K SLOC code base over the years to handle special and weird cases observed and reported in from the field.
As you can guess, it’s no one’s fault that the code is a tangled mess. It’s because the second law of thermodynamics has been in action doing its dirty work destroying the system without being periodically harnessed by scheduled acts of husbandry. A handful of maintenance developers imbued with a sense of personal responsibility and ownership have tried their best to refactor the beast into submission; under the radar.
Because the code is CPU intensive and single threaded, it’s not scalable to higher input data rates and its viability has hit “the wall”. Thus, besides refactoring the existing functionality into a more maintainable design, I have to simultaneously morph the mess into a multi-threaded structure that can transparently leverage the increased CPU power supplied by multicore hardware.

Note that redesigning for distributed flexibility and higher throughput doesn’t come for free. Essential complexity is added and additional latency is incurred because each input sample must traverse the 3 thread pipeline.
Piece of cake, no? Since lowly “programmers” are interchangeable, anyone could do it, right? I love this job and I’m having a blast!
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

